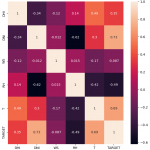
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
#DataFrame 열 삭제
train = train.drop(['intensity'], axis =1)
def feature_change(train):
# type
train['type'] = train['type'].map({'white': 0, 'red' : 1})
#sweetness
train['sweetness'] = train['sweetness'].map({'dry': 0, 'off-dry' : 1, 'medium-sweet' : 2})
return train
train = feature_change(train)
train.info()
train.isnull().sum()
train = train.rename(columns={'volatile acidity':'VA'})
train = train.rename(columns={'fixed acidity':'FA'})
train = train.rename(columns={'free sulfur dioxide':'FSD'})
train = train.rename(columns={'total sulfur dioxide':'TSD'})
train = train.rename(columns={'citric acid':'CA'})
------------------------------
import os
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train = pd.read_csv('train.csv')
#DataFrame 열 삭제
train = train.drop(['intensity'], axis =1)
def feature_change(train):
# type
train['type'] = train['type'].map({'white': 0, 'red' : 1})
#sweetness
train['sweetness'] = train['sweetness'].map({'dry': 0, 'off-dry' : 1, 'medium-sweet' : 2})
return train
# sweetness 가 꼭 필요한가?
# 와인 색도 꼭 필요함?
# intensity도 NaN이라 그냥 다 지웠는데...
# object는 다 없애버려도 그만아닐까
train = feature_change(train)
train.info()
train.isnull().sum()
#
# 의사결정나무로 1차제출
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
print(train.shape)
print(train.describe())
print(train.iloc[:,-1].value_counts())
x_data = train.iloc[:,:-1]
y_data = train.iloc[:,-1]
print(x_data.shape)
print(y_data.shape)
x_data = x_data.values
y_data = y_data.values
x_train, x_test, y_train, y_test = model_selection.train_test_split(x_data, y_data, test_size=0.32)
estimator = DecisionTreeClassifier(criterion='gini', max_depth=None, max_leaf_nodes=None, min_samples_split=2, min_samples_leaf=1, max_features=None)
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_train)
score = metrics.accuracy_score(y_train, y_predict)
print(score)
y_predict = estimator.predict(x_test)
score = metrics.accuracy_score(y_test, y_predict)
print(score)
---------------------------------------------------------------------------------
Q) 어떤 경우가 Data leakage에 해당되나요?
: Test 데이터셋은 기본적으로 '아예 볼 수 없다' 라는 가정 하에 진행해야 합니다.
- label encoding, one-hot encoding 시 test 데이터 셋 활용하여 encoder를 fit하는 경우
- data scaling 적용 시 test 데이터 셋 활용하여 scaler를 fit하는 경우
- pandas의 get_dummies() 함수를 test 데이터셋에 적용하는 경우
- test 데이터 셋의 결측치 처리 시 test 데이터 셋의 통계 값 활용
- test 데이터 셋을 EDA하여 얻은 인사이트를 통해 학습에 활용하는 경우
- test 데이터 셋을 학습 과정에 사용하는 모든 행위 (test 데이터셋은 추론에만 활용되어야 합니다)
- test 데이터 셋의 데이터 개수 정보를 활용하는 경우 (실제 test 데이터셋은 몇개가 입력으로 들어올 지 모르기 때문)
- 위 예시 외에도 test 데이터 셋이 모델 학습에 활용되는 경우에 Data leakage에 해당됨.
 트레이닝세트하고 테스트셋 설명좀
트레이닝세트하고 테스트셋 설명좀